“The ratio of people to cake is too big.” –Milton
Finally getting around to writing-up what I have been doing with solveit since completing the AoC puzzles earlier this year. For the last month or so, I have gone pretty far down the rabbit hole of trying to further compress the tokens from an existing driving video pipeline ultimately used to train a world model for the Comma AI open source driver assistance system. Note: The compression challenge technically ended last July but I didn’t let that stop me ;-)
This particular pipeline begins with H.265 HEVC video coming off of a single front facing camera which is then compressed through a VQ-VAE encoder. The encoder in turn outputs these compressed tokens, also known as a codebook. Compared to many of the more mainstream driving systems out there, the single camera encoder/decoder approach is a hacker friendly starting point as it is not uncommon to see multiple cameras and other sensors like LiDAR and RADAR as additional inputs to these systems. For example, consider Nvidia’s Hydra-MDP architecture as one such more complex approach:
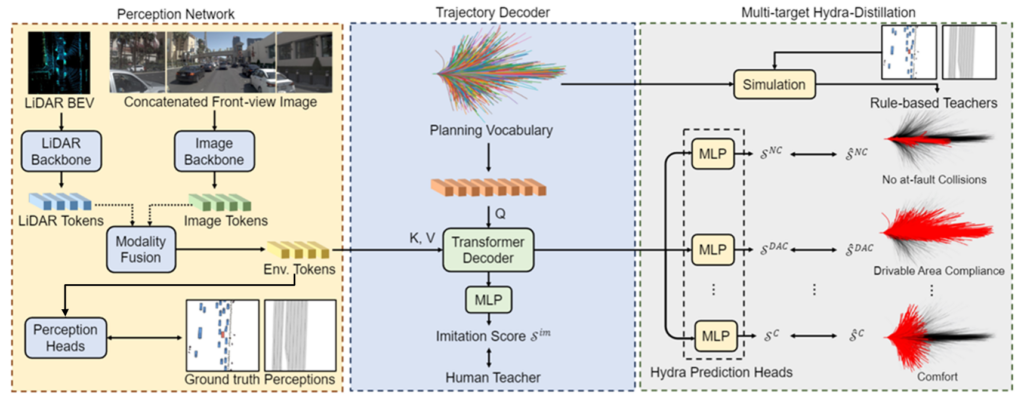
Source: Nvidia
…and in case you need a reminder of what a Hydra actually is:

Source: ??
I am really in no position to say which approach wins in the marketplace but I have a pretty good idea who is currently selling more hardware ;-) With that said, in the near-to-mid-term, it looks to me like there will continue to be room for both complex and hacker-friendly systems to flourish.
Leaning-in on the fast ai approach I started with getting the data loaded but of course I am not content with just downloading the data and calling it a day. I wanted to stream the data from the source, which in this case is a public Hugging Face dataset. I also wanted the ability to select various splits and segments of the dataset as this would provide me with the flexibility I was looking for during the data loading phase of my explorations. In this case solveit not only created the core functionality but it also provided me with the additional flexibility I was going to eventually need when running a couple or more full splits through my encoder/decoder components.
Once I had a few segments, it was time to explore the data and the various approaches to compression. This is where solveit really shines because it enabled me to quickly try things that would have otherwise taken me too long to figure out how to code. Some examples of my explorations include Run-Length Encoding (RLE), Quantization, and Entropy Coding just to name a few. As you will soon see in the gist, I also tried combining approaches looking for some way to find an advantage. Spoiler alert: It is challenging to get a high lossless compression rate on data that has already been encoded. The mid ~2.4x, ~2.5x might be as good as it gets?
While there is room for many improvements, here are what I consider the best bits so far:
https://gist.github.com/c5huracan/f13725ed896754ee2896c1522cf80469
I will tell you that I know of at least one big problem with that gist. If you know what it is and feel the need to respond please redact it so others can study and learn from it first. Any other feedback is appreciated.
Personally, I still need to slowdown and work line-by-line to more thoroughly understand what each variable and what each line of code is doing. As many will know this is something that Jeremy has been teaching at least since 2016~2017 and likely longer. I also know that I can be impatient, so I will need to continue to work on that as well!
Also, I am personally very grateful for the early access to solveit (the tools and the techniques), this community, and my entire experience. Thank you all!